Your proposal content library is a tax, not an asset.

Published on March 30, 2026
Most proposal teams treat their content library as a prerequisite.
Before you can automate anything, the logic goes, you need to populate a database, tag every answer, and then categorize by topic, by client vertical, and by contract vehicle. Then you have to assign owners, schedule quarterly reviews, retire stale entries, and then hire someone to manage it all.
This has been the accepted starting point for proposal automation for decades. And it is the single biggest reason most proposal technology investments take six months to show any return, and also why the system’s responses are rarely trusted.
A new generation of AI-native proposal platforms is challenging that assumption directly.
AI-native software often have what is call a self-building knowledge base that grows as a byproduct of doing the work, not exist as a precondition for starting it. For revenue leaders running lean teams against aggressive bid calendars, the distinction is worth real money. And for busy proposal managers, the distinction is focusing on revenue-generating work.
Does the proposal content generating come from nothing? Absolutely not. But instead content is generated from more updated content that lives within your organization already.
A self-building knowledge base is a proposal automation architecture that indexes existing company documents (technical documentation, SharePoint files, call recordings, email chains), drafts responses using retrieval-augmented generation, and improves automatically as subject-matter experts correct and approve answers. The platform handles content discovery and organization without migration projects or dedicated library staff. It gets smarter with every RFP your team touches.
Why proposal content libraries cost more than teams expect
Traditional RFP platforms (Responsive, Loopio, Upland Qvidian) rely on a curated content library at their core. The software is only as good as the data your team puts into it, which is still true, but in an entirely different way. With traditional platforms, someone has to build and maintain the library before the tool earns its keep.
A McKinsey Global Institute study found that knowledge workers spend nearly 20% of their time just searching for internal information. For proposal teams, the problem is worse because the content they search for also has to be maintained. For a mid-market company responding to 10 to 20 RFPs per month, maintaining that library is a full-time role.
In practice, most organizations assign it to a proposal content manager, a role that barely exists on even the largest teams. The result is that content goes stale within weeks, confidence in suggested answers drops, and the team reverts to copying and pasting from last quarter's winning submission - which is just as risky.
✸ Most proposal technology investments take six months to show any return. The content library build-out is the bottleneck.
The industry calls this "garbage in, garbage out." AI output quality depends entirely on data quality, and no amount of generative polish fixes a weak foundation. They are right about the principle. The question is whether the principle requires a proposal-maintained library.
What is a self-building knowledge base for proposals
Trampoline AI, a Montreal-based proposal technology startup, is the clearest example of a different architectural bet. Rather than asking teams to populate a library before they start, Trampoline indexes what already exists in SharePoint documents, Slack, Teams conversations, email chains, and past proposals sitting in file shares.
The system uses semantic search and retrieval-augmented generation to find relevant content wherever it lives, then surfaces the actual source material (not a hallucinated answer) alongside its AI-drafted response. When a subject-matter expert corrects or approves an answer, that correction feeds back into the system. The next time a similar question appears in a different RFP, the AI uses the expert-validated version.
✸ A self-building knowledge base is a content repository that grows from expert corrections made during normal RFP work, requiring no separate curation, tagging, or maintenance process.
The founders describe this as burning your wikis. The sentiment is deliberately provocative, but the operational implication is practical; your team spends zero hours on content migration, zero hours on manual tagging, zero hours on quarterly library audits, and zero hours chasing SMEs for content reviews. The knowledge base grows as a side effect of answering RFPs.
How self-building knowledge bases improve proposal win rates over time
The architectural difference matters less as a technology debate and more as a revenue capacity question.
Each answered RFP teaches the system, and each expert's edit improves the next suggestion. As your team indexes more documents, the searchable knowledge base expands without anyone maintaining it. The team that uses this kind of platform for twelve months has a measurably better tool than the team that started yesterday, without anyone spending a single hour on content maintenance to produce that improvement.
This is a compounding return curve, and it has a direct analogue in how CROs think about pipeline. A tool that gets 5% better at drafting proposal answers every quarter doesn't just save time. It increases the number of bids your team can submit with the same headcount. If your constraint is proposal capacity (you are leaving winnable opportunities on the table because your team cannot write fast enough), the compounding effect converts directly into revenue coverage.
Contrast that with a traditional content library, which degrades over time unless someone actively maintains it. One approach appreciates in value. The other depreciates. Both cost money, but only one requires ongoing labor to prevent decay.
What to consider before replacing your proposal content library
Revenue leaders evaluating this category should weigh the architectural advantage against real operational risk.
The broader point holds regardless of whether AI-fed libraries like Trampoline specifically is the right vendor for your team. The architectural pattern (index what exists, learn from corrections, compound over time, require zero content maintenance) will appear in more platforms over the next eighteen months. Several established vendors are moving in this direction, though most are retrofitting the capability onto existing library-first architectures rather than building around it. Loopio's 2026 RFP Trends and Benchmarks Report confirms this tension, where teams are adopting AI at scale, but bandwidth constraints and content maintenance remain the dominant bottlenecks.
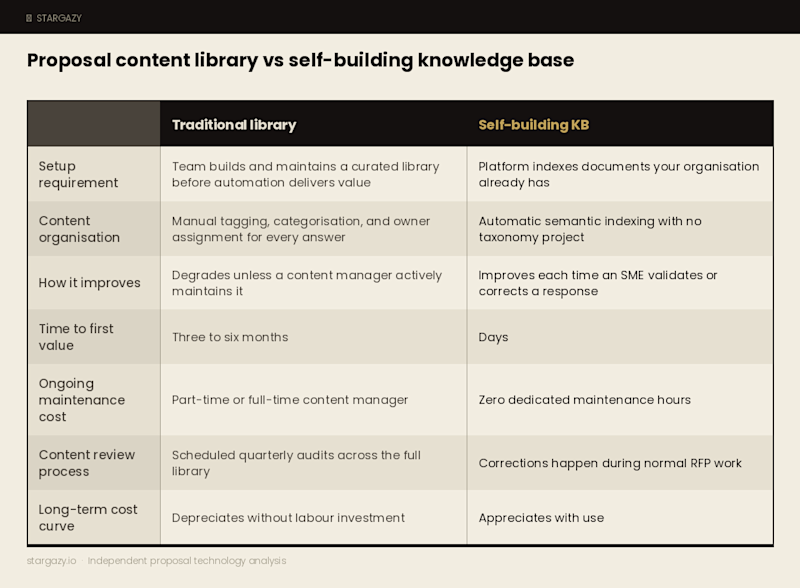
Proposal content library vs self-building knowledge base: side-by-side comparison
The traditional content library model. Your team builds and maintains a curated content library before automation delivers any value. Your team must tag, categorize, and assign every answer, then review the whole library on a recurring schedule. The platform degrades without that ongoing, significant labor. Time to first value is usually three to six months. The ongoing cost is a part-time or full-time content manager.
The self-building knowledge base model. The platform indexes documents your organization already has and drafts answers using retrieval-augmented generation. It improves each time a subject-matter expert validates or corrects a response. Your team skips the migration project, the tagging taxonomy, and the scheduled content audits entirely. Time to first value is usually in days. And the ongoing cost is zero dedicated maintenance hours. The platform appreciates with use rather than depreciating without it.
How to evaluate proposal automation software in 2026
If you are evaluating proposal automation in 2026, ask every vendor these two questions. The answers separate the traditional content library model from a self-building knowledge base.
How long before my team sees measurable time savings?
If the answer involves a content migration project, a tagging exercise, or a library population phase measured in months, you are looking at the traditional model. A self-building knowledge base that indexes your existing sources should produce usable first-draft answers within the first week.
Does the tool get better with use, or does it require my team to make it better?
A platform that learns from expert corrections and grows its knowledge base as a byproduct of daily work has a fundamentally different cost curve than one that requires a dedicated content manager to keep it current.
✸ Two questions separate old-model platforms from new ones. How long before my team sees time savings? Does the tool get better with use, or do I need staff to make it better?
The revenue leader's version of both questions is simple. Can I submit more bids next quarter without hiring anyone?
If the tool requires a six-month library build before it starts earning its keep, the honest answer is no.
If the tool indexes what you already have and improves with every RFP you touch, the answer might be yes, within weeks.
For lean proposal teams competing against better-resourced competitors, that difference in time-to-value is the whole argument.
✹
You can compare vendors and shortlist platforms at Stargazy's proposal technology directory.
✹
Frequently asked questions about proposal content libraries and self-building knowledge bases
What is a self-building knowledge base for proposals? A self-building knowledge base is a proposal automation architecture that indexes existing company documents, such as SharePoint files, past proposals, email chains, and call recordings, then drafts RFP responses using retrieval-augmented generation. It improves automatically each time a subject-matter expert corrects or approves an answer, with no separate content curation, tagging, or maintenance process required.
How long does proposal automation software take to set up? It depends on the architecture. Traditional platforms that rely on a curated content library typically take three to six months before teams see measurable time savings, because the library has to be populated, tagged, and reviewed first. Platforms built around a self-building knowledge base can produce usable first-draft answers within the first week by indexing documents the organisation already has.
Why do proposal content libraries fail? Most proposal content libraries fail because maintenance is underestimated. Content goes stale within weeks, suggested answers lose trust, and teams revert to copying from previous submissions. The role required to keep the library current, a dedicated proposal content manager, rarely exists on mid-market teams, so the library degrades faster than it was built.
What is the difference between a content library and a self-building knowledge base? A traditional content library requires a team to build, tag, and maintain a curated answer database before the platform delivers value. A self-building knowledge base indexes existing company documents automatically and improves through expert corrections made during normal RFP work. One depreciates without ongoing labour. The other appreciates with use.
Can proposal teams automate RFP responses without a content library? Yes. AI-native platforms that use retrieval-augmented generation can draft proposal responses by searching across existing company documents rather than relying on a pre-built content library. The trade-off is that response quality depends on what documents are available to index, so teams with poorly organised or outdated source material may still need to clean up their documentation, though not to the extent required by a traditional library-first platform.

Christina Carter
I’m the founder of stargazy, the intelligence network for capture and proposal professionals. With 15+ years of running presales and proposal teams for B2B Enterprise, UK Public Sector, and US GovCon around the globe.